PS/백준
[백준/9537] 잘생긴 GCD (Python)
- -
Problem : https://www.acmicpc.net/problem/9537
9537번: 잘생긴 GCD
입력은 여러개의 테스트 케이스로 이루어진다. 첫 줄에는 테스트 케이스의 수를 의미하는 T 가 주어진다. 각 각의 테스트 케이스들은 두 줄로 구성되는데, 첫 줄은 수열의 크기 n ( 1 ≤ n ≤ 100
www.acmicpc.net
Difficulty : Platinum 2
Status : Solved
Time : 00:50:47
문제 설명
더보기
어떤 길이가 양의 정수인 수열은 잘생긴 GCD 라는 값을 가질 수 있다. 잘생긴 GCD란 그 수열의 모든 원소들의 최대공약수에 수열의 길이를 곱한 값으로 정의된다.
당신의 임무는 수열이 주어질 때(a1, ... , an) 그 수열의 연속된 부분수열들의 잘생긴 GCD 중 가장 큰 값을 구하는 것이다.
입력 및 출력
더보기
입력
입력은 여러개의 테스트 케이스로 이루어진다. 첫 줄에는 테스트 케이스의 수를 의미하는 T 가 주어진다. 각 각의 테스트 케이스들은 두 줄로 구성되는데, 첫 줄은 수열의 크기 n ( 1 ≤ n ≤ 100 000 )이 주어진다. 두 번째 줄은 수열 a1, a2, ... , an 이 하나의 공백을 사이에 두고 주어지고 수열의 값은 1 이상 1,000,000,000,000 이하의 값을 가진다.
출력
각 각의 테스트 케이스에서 주어지는 수열의 연속 된 부분수열 중 잘생긴 GCD의 값이 가장 큰 수열의 잘생긴 GCD를 출력한다.
입력 예시
1
5
30 60 20 20 20
출력 예시
80
풀이
두 수의 gcd값을 기준으로 생각해 보면, gcd(a, b)의 경우의 수는 경우의 수가 매우 적다. a = b라면 gcd(a, b) = a가 되겠지만, 그 이외의 경우를 살펴보자.
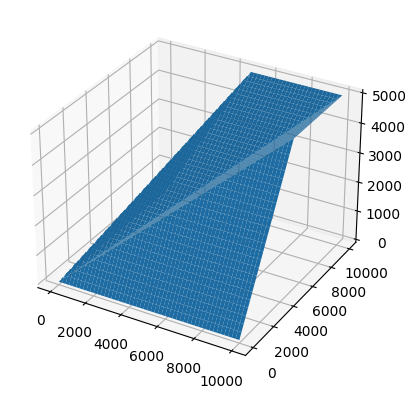
이 그래프는 1 ~10000 값 사이의 x != y인 gcd 값의 누적 max값을 나타낸다.
가령, (x, y, z)에서 z값은 max(gcd(i,j), 1 <= i <= x, 1<= j <= y, i != j )를 의미한다. 즉 이외의 경우에는 gcd값이 절반 이하로 줄어들며, 우리는 그 절반 이하의 값을 고려하기만 해주어도 충분하다.
i번째 숫자 N[i]를 탐색할 때, i번째 이전의 gcd값들과 그 gcd값이 맨 처음 등장한 좌표를 저장해 두었다고 가정하자. 이를 자료구조를 stk이라고 두자. i번째 이후의 stk 갱신은 다음과 같이 이루어진다.
- new_stk[N[i]] = min(i, stk[N[i]])
- stk에 저장된 gcd값과 최소 좌표값을 key, val이라고 두면
- new_stk[gcd(N[i], key)] = min( new_stk[gcd(N[i], key)], val )
- 새로운 각 값에 대해
- ans = max(ans, (i - val + 1) * key)
로 갱신해 줄 수 있다.
풀이 코드
from collections import defaultdict
import sys
input = sys.stdin.readline
def gcd(a, b) :
while b :
a, b = b, a%b
return a
def solve() :
N = int(input())
nums = list(map(int, input().split()))
stk = defaultdict(lambda : N)
ans = 0
for i in range(N) :
stk[nums[i]] = min(stk[nums[i]], i)
next_stk = defaultdict(lambda : N)
for key, val in stk.items() :
g = gcd(nums[i], key)
next_stk[g] = min(next_stk[g], val)
ans = max(ans, g * (i-next_stk[g]+1))
stk = next_stk
print(ans)
for _ in range(int(input())) :
solve()
'PS > 백준' 카테고리의 다른 글
| [백준/26149] 선물의 재분배 (Python) (1) | 2024.02.08 |
|---|---|
| [백준/25606] 장마 (Python) (1) | 2024.02.07 |
| [백준/14287] 회사 문화 3 (Python) (1) | 2024.02.04 |
| [백준/16678] 모독 (Python) (0) | 2024.02.04 |
| [백준/17226] 묘수풀이: 모독 (Python) (1) | 2024.02.04 |
Contents
소중한 공감 감사합니다