AI, ML/기타 정리
[파이토치 2.0] Scaled Dot Product Attention
- -
이전 글에서는 pytorch 2.0에서 무엇이 달라졌는지 짚고 넘어갔다.
2023.04.06 - [AI, ML/기타 정리] - [파이토치 2.0] 어떤 점이 달라졌을까?
[파이토치 2.0] 어떤 점이 달라졌을까?
22년 12월, 파이토치의 대격변이 일어났다. https://pytorch.org/blog/pytorch-2.0-release/ PyTorch An open source machine learning framework that accelerates the path from research prototyping to production deployment. pytorch.org 파이토치 2
magentino.tistory.com
torch.complie의 파이썬으로의 회귀. 그리고 이를 위한 다양한 스킬셋에 대해 살펴보았다. 성능 관련 기술 중 SDPA(Scaled Dot Product Attention)에 대해 언급했는데, 이에 대해 먼저 간략하게나마 소개하고자 한다.
Scaled Dot Product Attention? 왜 필요한거죠?
우선 Scaled Dot Product Attention에 대해 짚고 넘어가야 한다. 배경 지식이 없다면 네 단어 모두 아리송할 것이다. 하지만 이 attention과 attention을 이용한 Transformer는 2010년 중후반부터 NLP, Sequential, Vision task 모두를 평정한 baseline이 되어버렸기에, 이에 대한 이해는 필수이다!
Scaled Dot Product Attention 기법은 트랜스포머 모델이 맨 처음으로 정립된 논문 'Attention is all you need(NIPS 2017)'에 처음으로 소개되었다.(https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html)
Attention is All you Need
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
papers.nips.cc
구체적으로는, 쿼리(Query), 키(Key), 값(Value)를 이용해 연산하는 기법이다. 우리가 최종적으로 알고 싶은 건 쿼리를 이루는 각 요소의 '집중도(Attention)'이다. 즉 쿼리의 성분을 키를 가지고 '어떤 것이 중요한 정보인지'를 수치화해서 나타내고 싶고, 이렇게 구한 '정보'를 키에 반영하여 이용하는 게 목적이라고 볼 수 있다. 이는 쿼리와 키 사이의 '유사도'를 가지고, 이 유사도에 대응되는 값을 통해 최종적으로 쿼리의 집중도를 구해주는 방식이다. 원래는 자연어처리-NMT(Neural Machine Translate)에서 나온 개념으로, 번역하고자 하는 각 위치의 단어를 예측할 때 다른 위치의 단어들 중 도움이 되는 단어만 '집중해서' 활용한다는 개념으로 사용되었다.
먼저 쿼리와 키의 유사도를 어떻게 구할까? 쿼리와 키는 벡터 혹은 매트릭스로 나타낼 수 있다. 이를 테면 쿼리 벡터를 Q, 키 벡터를 K라 두자. 유사도(여기서부턴 attention score라고 칭하겠다)를 구할 수 있는 방법은 여럿이지만, 본 논문의 저자는 크게 다음 두 가지를 꼽았다.
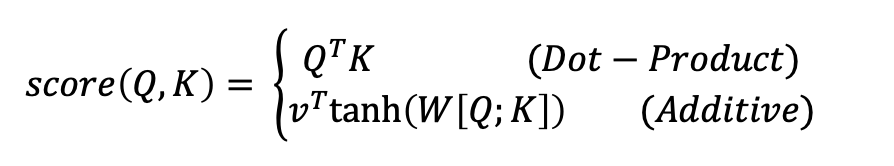
- Dot-product Attention : Luong Attention이라고도 한다. 쿼리와 키를 단순히 행렬곱시켜버린다! 이 결과는 쿼리에 각 원소에 대한 키의 각 원소의 유사도 매트릭스와 비슷하게 나온다.
- Additive Attention : Bahdanau Attention이라고도 한다. 쿼리와 키를 concat해서(한 줄로 이어버린다!), tanh를 활성화함수로 갖는 한 층의 Neural Network에 통과시킨다. 이 값이 Attention score가 된다!
즉 여기서 말하는 Attention scoring은 Dot product(즉 행렬곱)를 사용한 셈이다!
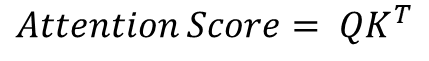
행렬곱의 경우, 곱셈을 통해서 각 성분의 '코사인 유사도'를 구할 수 있다는 특징이 있다. (코사인 유사도까지 설명하자면 선형대수까지 들어가야 할 것 같다...) 그리고 이 attention score는 천차만별의 값이 나오므로, 상대분포의 비교를 위해 총합이 1이 되도록 Softmax 함수로 통과시켜줄 필요가 있다. 즉 식으로 표현하면
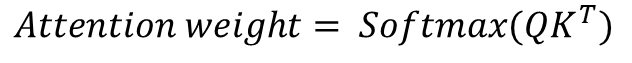
가 된다! 이를 attention distribution(혹은 attention weight)이라 칭한다.
그런데 논문 저자가 말하길, 이렇게 구현한 Dot product는 쿼리의 길이가 길어질수록 Additive에 비해 성능이 하락한다고 한다! 따라서 이를 normalize해줌으로써 성능을 높여줄 필요가 있었다. 즉 이를 위해 쿼리 길이의 제곱근인 sqrt(dk)를 나누어 주었고, 이를 Scaling이라고 칭한다. 즉 정리하면
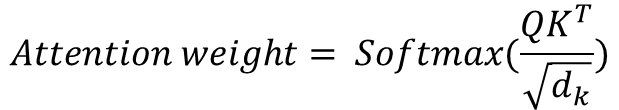
가 된다!
최종적인 attention value는 여기에 value값을 또 Dot product하여서...
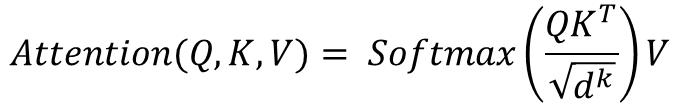
로 나타내어진다! (이건 따로 정리해서 논문 리딩에 활용하봐도 괜찮을 것 같다)
자, 여기서 문제가 하나 발생한다. 최종적인 Attention을 수행할 때 총 두 번의 Dot-Product가 발생하며, 이는 쿼리의 길이가 커질수록 기하급수적인 연산량과 메모리 사용량을 가져온다. 또한, Multihead attention 등은 심지어 이러한 Attention 연산을 병렬적으로 수행하여야 한다! 기본적인 Transformer 모델보다도 훨씬 더 깊고 넓어진, 이미지 처리 분야까지도 넘보는 현 상황에서 이 연산량 및 메모리 사용을 효율적으로 해결해야 할 필요가 있었다.
SPDA : 파이토치의 새로운 가족들
문제는 그동한 파이토치는 이러한 점에 대해 고려하지 못했다. 파이토치에서는 이러한 SPDA를 메모리상에서 효율적으로 적용하기 위해선 서드파티 알고리즘을 사용해야만 했다.FlashAttention, xformer등이 대표적이다.

파이토치의 SPDA는 이들을 파이토치의 새로운 가족으로 맞이하였고, 이들을 지원하는 새로운 함수 torch.nn.functional.scaled_dot_product_attention를 사용하면, query, key, value만으로도 간단하게 위 알고리즘의 이점을 얻으며 SPDA를 수행할 수 있다!
- 효율적인 메모리 연산이 필요할 때 : FlashAttention, xformer로 연산을 시행한다.
- CPU밖에 사용할 수 없을때 or 보다 정밀한 연산이 필요할 때 : Torch C++로 구현된 내부 연산을 시행한다.
또한, 이들은 torch.complie을 적용하였을 때 자동적으로 상황에 맞는 알고리즘을 채용해준다.


더 중요한 점. transformer, self-attention 등은 이 SPDA를 기본 매커니즘으로 사용한다. 그말인즉슨, 이 함수를 통해 multi-head self attention, transformer와 같은 모듈을 연산하는 데 사용할 수 있다. 아직은 SPDA 자체가 beta 버전이므로 실제로 적용되지 않았지만, 어느 정도 디버깅이 되고 나면 바로 적용될 것 같다는 개인적인 생각을 품어 본다. huggingface 등의 거대 라이브러리도 파이토치 기반 모델이 많이 배포되는 만큼 서서히 영향을 미칠 것처럼 보인다.
>>> # Optionally use the context manager to ensure one of the fused kernels is run
>>> query = torch.rand(32, 8, 128, 64, dtype=torch.float16, device="cuda")
>>> key = torch.rand(32, 8, 128, 64, dtype=torch.float16, device="cuda")
>>> value = torch.rand(32, 8, 128, 64, dtype=torch.float16, device="cuda")
>>> with torch.backends.cuda.sdp_kernel(enable_math=False):
>>> F.scaled_dot_product_attention(query,key,value)(출처 : Pytorch docs)
이런 식으로, 내가 원하는 backend를 지정해 주는 것도 가능하다! 더 자세한 사항은 Docs를 참조해보도록 하자.
자, 이런 식으로 SDPA를 이해하고 다시 다음 블로그 포스팅(https://pytorch.org/blog/accelerated-diffusers-pt-20/)으로 돌아가보자.
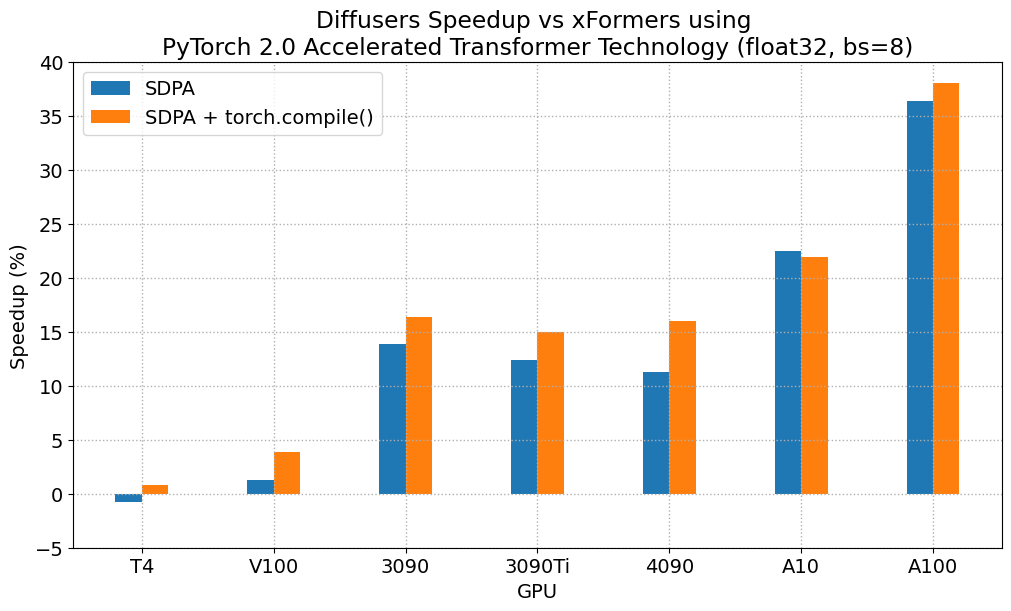
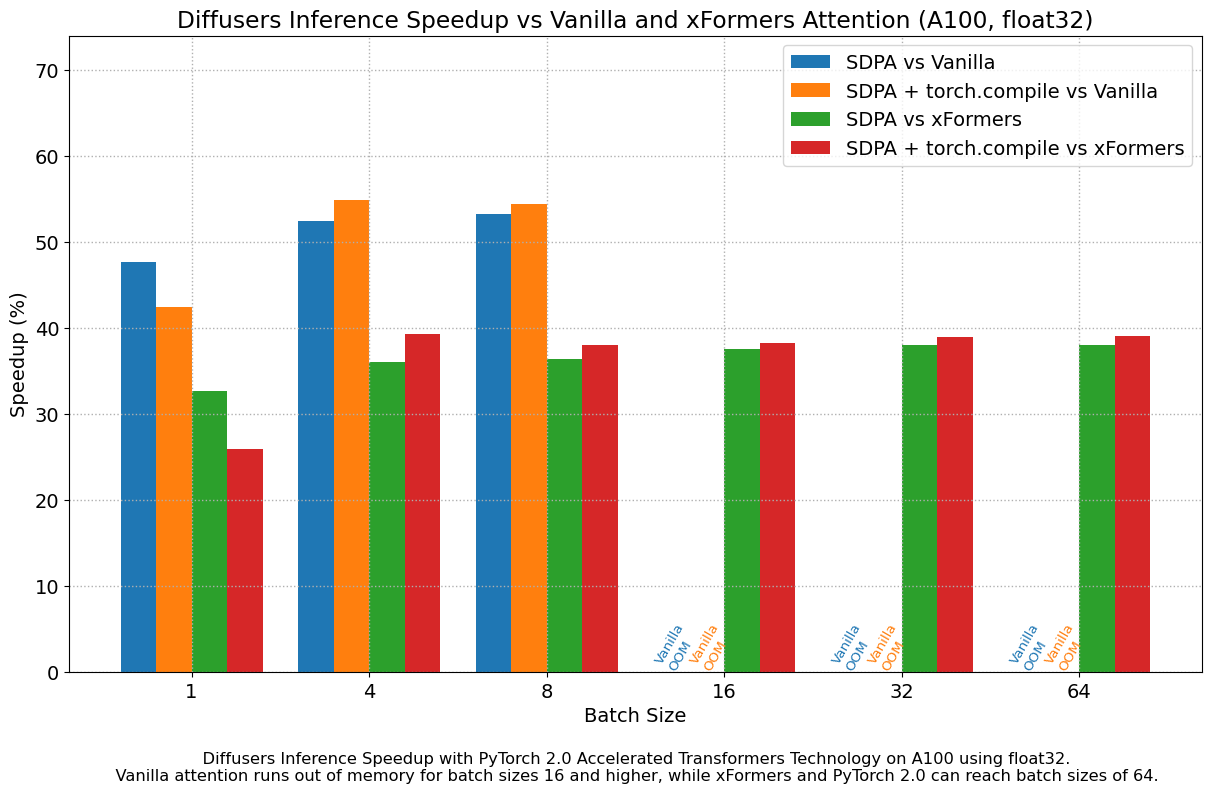
디퓨저 모델을 사용하며 이 SDPA를 적용하였을 때, T4 GPU를 제외한 모든 경우에서 일관적으로 speedup을 볼 수 있었다. 특히 torch.complie을 같이 적용하였을 때 더 연산 속도가 높아지는 경우 역시 보여주고 있다. 이전 버전에서의 vanila attention으로 연산하였을 때와도 비교해보면, vanila로만 진행했을 때, vanila에 xformer를 적용하였을 때보다 일관적으로 연산속도 향상을 보여준다는 사실 역시 눈여겨볼 수 있다!
마치며...
사실 이 포스트에서 GNN 및 Torch.complie 비교 실험 등을 같이 진행해보고 싶었는데, 여러 일이 겹치다보니 다음 포스팅으로 미루게 되었다. 이 시리즈가 어떻게 끝날지(그리고 Pytorch 2.0을 어디까지 이해해볼 수 있을지) 아직은 미지수이지만, 일단 차근차근 진행해나가고 있다는 점에 포인트를 두며 글을 줄인다.
'AI, ML > 기타 정리' 카테고리의 다른 글
| [파이토치 2.0] 어떤 점이 달라졌을까? (0) | 2023.04.06 |
|---|
Contents
소중한 공감 감사합니다